【说明】文字匹配功能的使用方法
1. 简介
观前提醒:
强烈建议先阅读 → 【说明】辅助工具--精准查询的使用方法
再来看本文,理解会更顺畅!
假设我们有两块数据,分别称为“新数据”和“旧数据”。
本功能的核心目标是:在“新数据”的每一项右侧,自动填入与其最相似的一项“旧数据”。
听起来可能有点抽象?别急,看后面的例子就明白了。
2. 基础概念
理解原理是高效使用的关键——
一旦掌握,它将在实际工作中为你节省巨量时间,绝对值得花几分钟搞懂。
注意:操作本身非常简单,重点在于理解设计意图。
来看一个实际案例:
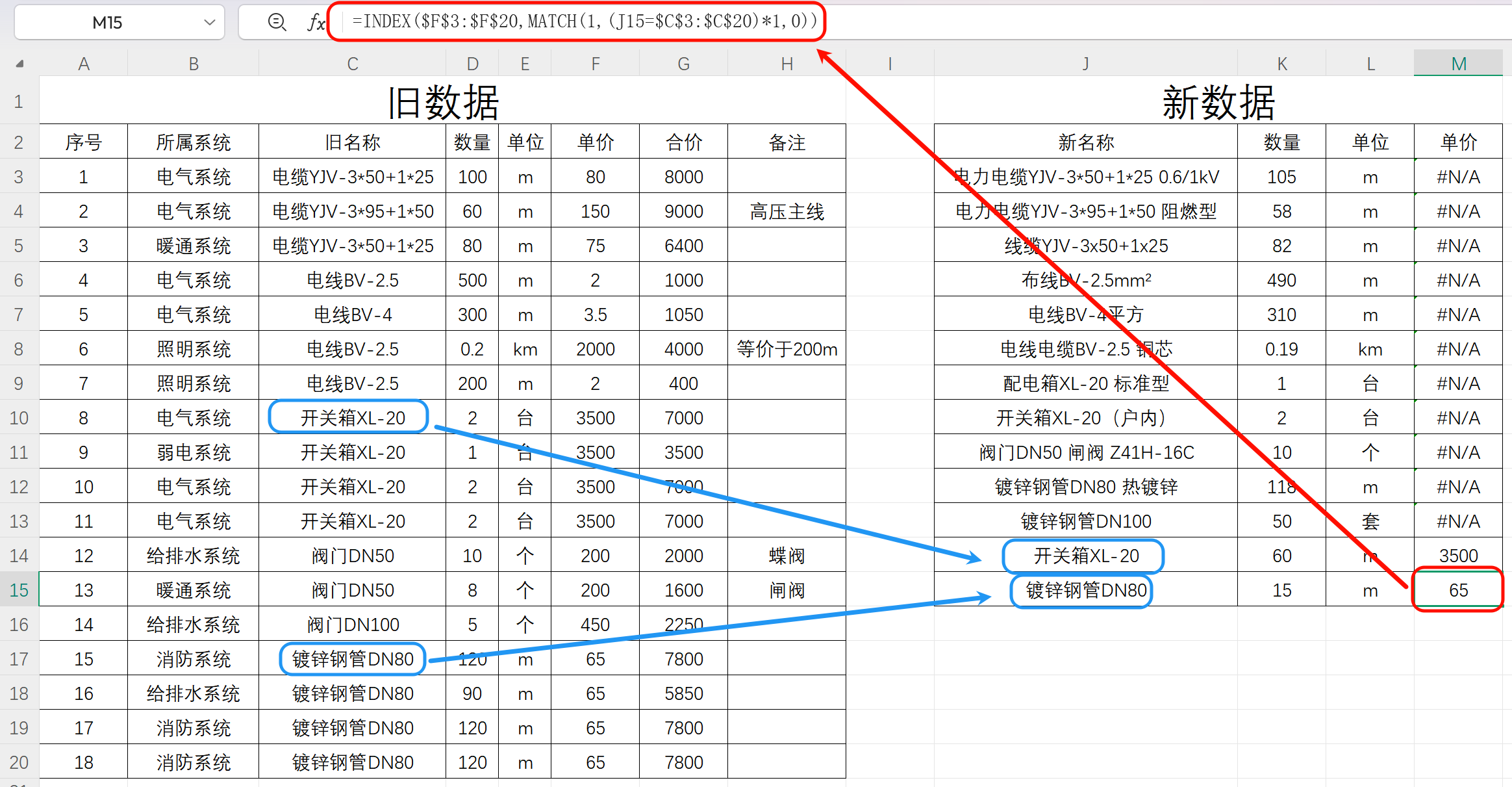
如上图所示:
- 左侧是“旧数据”(含完整信息,如单价)
- 右侧是“新数据”(需要补充信息,如单价)
我们的目标是:
根据“新数据”中的材料名称,在“旧数据”中找到最相似的名称,并带回对应的“旧单价”。
这是一个常见需求:
“从另一张表里找相似项目,把它的价格、数量等信息带过来,用于参考或分析。”
常规做法是用 Excel 公式,如 VLOOKUP、XLOOKUP 或 INDEX+MATCH。
但问题来了——如图中所示,只有最后两项成功匹配,其余全部失败。
为什么?
因为公式要求名称完全一致。只要有一点不同(多字、少字、参数变化),就匹配不上。
而现实中,两张表的名称几乎不可能完全一样。
那怎么办?
这就是本工具的价值:
它会自动在“新数据”旁,匹配出一个最相似的旧名称——
你可以认为:这个名称和新名称大概率是同一种东西。
然后,你就可以用这个“匹配到的旧名称”作为桥梁,
通过公式去旧表中查找它(而不是查找新名称,因为用它是找不到的),并带回单价、数量等信息。
✅ 相当于:
本工具先解决了“名字对不上”的问题,
剩下的,交给熟悉的工具继续处理。
流程打通,效率翻倍。
3. 操作示例
如果概念已理解,操作就非常简单。看下图:
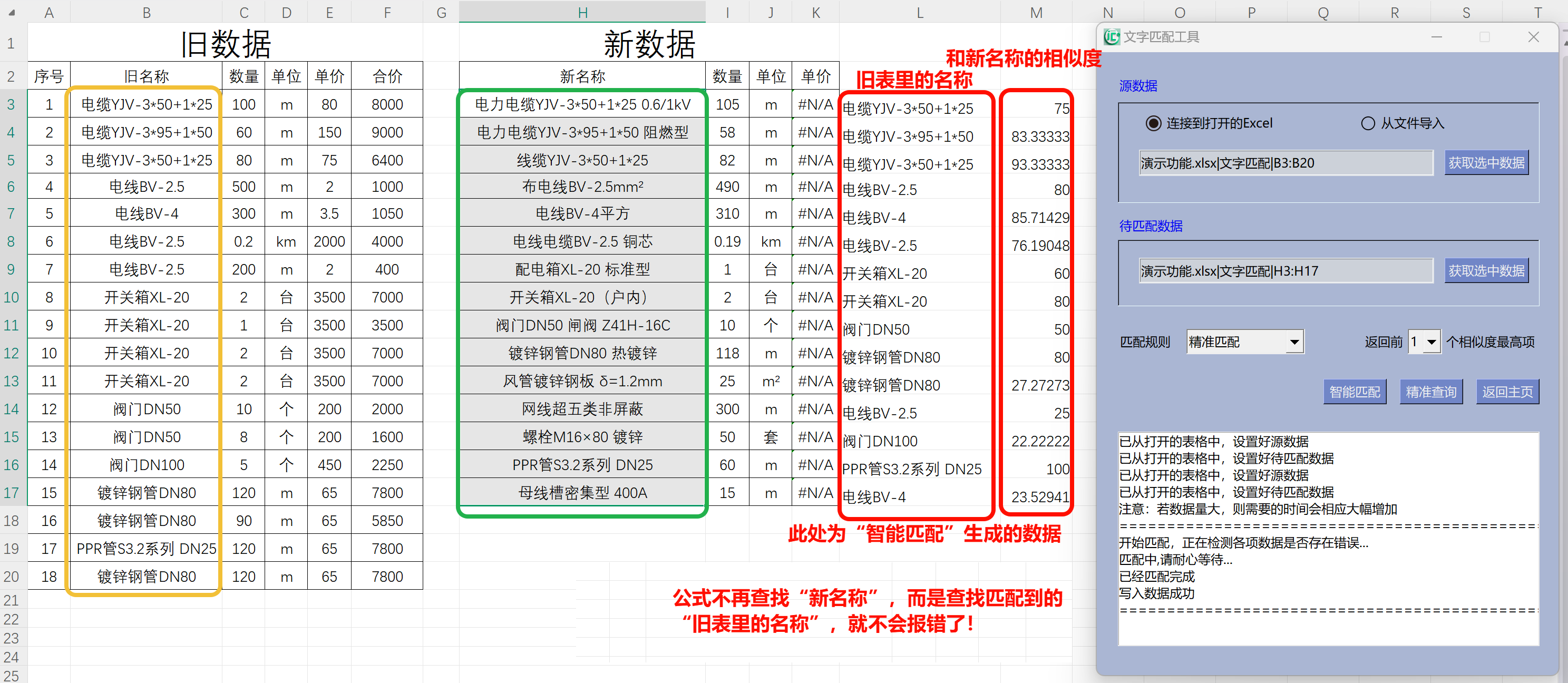
步骤如下:
- 选择源数据获取方式 → 选
连接到打开的Excel - 选择源数据范围 → 选黄框区域,点
获取选中数据 - 选择待匹配数据范围 → 选绿框区域,点
获取选中数据 - 选择匹配规则 → 一般选默认的“精准”即可
- 开始匹配 → 点
智能匹配,结果自动写入红框区域 - 精准查询(可选) → 点
精准查询,按提示操作(查找列 = 匹配到的旧名称,返回值 = 单价等)
⚠️ 注意事项
两个“获取”按钮的区别?
- 第一个:选源数据表(黄框)——参考用的完整数据表
- 第二个:选待匹配表(绿框)——需要补充信息的新表
关于“源数据获取方式”
除了“连接已打开的Excel”,还支持“从文件导入”(参考Save/Material文件夹示例)。
要求:① 文件为
.xls或.xlsx② 首行为列名
③ 必须包含“标准名称”列
“文件导入”的优势在于,可以将文件内的多种信息一同提取过来,不过需要对该文件进行编辑和维护。因此日常使用可“连接Excel”,更方便。
关于“匹配规则”
- 精准:通用推荐,综合评分(建议默认)
- 部分:包含部分文字就算相似
- 乱序:文字相同顺序不同就算相似
- 多段:中文、英文、数字各自分别比对后综合评分
✅ 大多数情况用“精准”即可。
点击 智能匹配 后,系统开始处理(耗时几十秒到几分钟)。
完成后,会在新数据最右侧自动加两列:
- 第1列:匹配到的旧名称
- 第2列:相似度得分(100 = 完全一致)
📌 示例(如图):
新名称:电力电缆YJV-3*50+1*25 0.6/1kV
匹配到:电缆YJV-3*50+1*25
相似度:75(非100,但已是最佳匹配)
4. 结果的使用与说明
原本用公式查“新名称”会失败(名称不一致),
现在改查 N 列的“匹配到的旧名称”,公式就能正确返回数值。
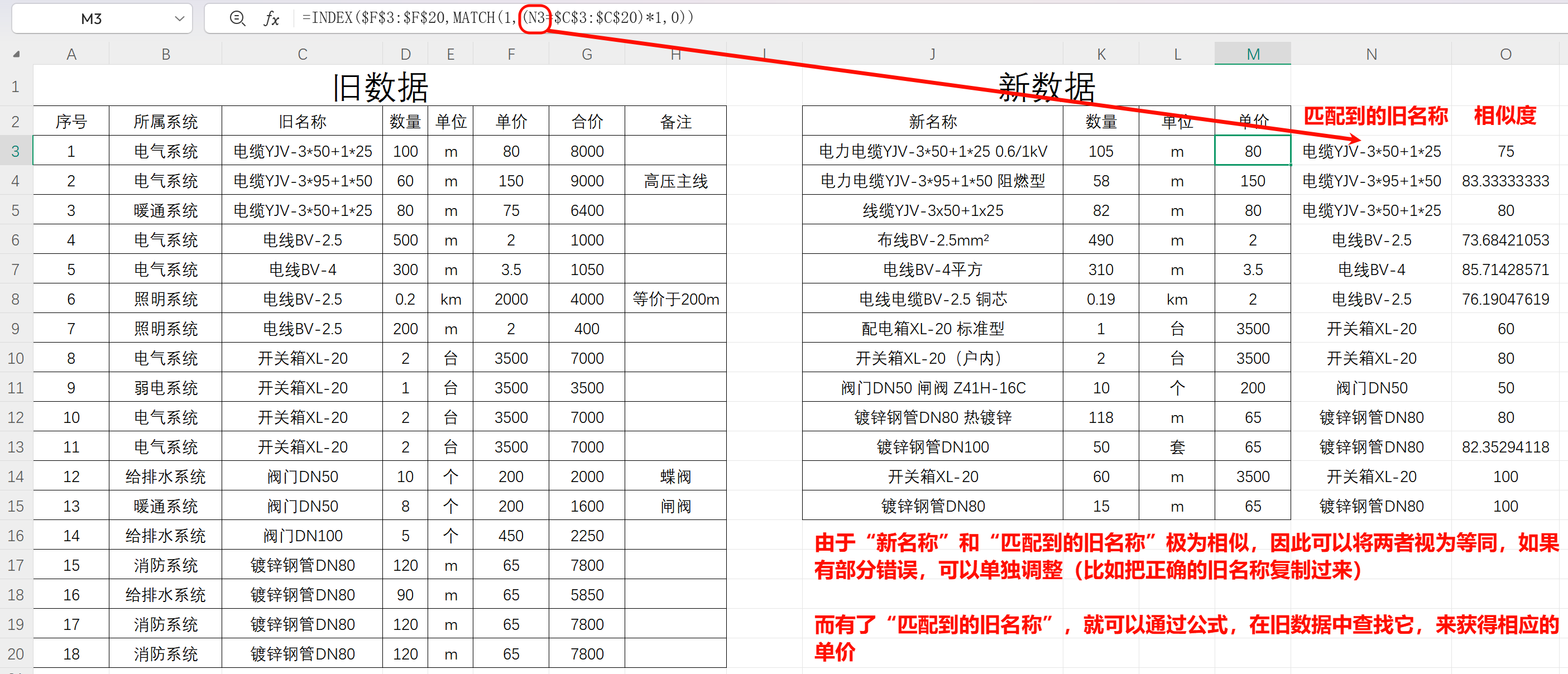
但注意:
相似度 < 100% 的结果,原则上需人工审核。
(即使100%,在“部分”“乱序”模式下也可能误匹配,所以推荐“精准”模式)
你可能会想:“那不还是得人工看?”
没错,但区别是:
👉 过去:一条条翻、查、复制粘贴
👉 现在:快速扫一眼,确认是否正确
工具帮你省下 30%~90% 的工作量,具体看两张表的命名风格是否一致。
更重要的是,我们采用“先匹配名称,再用公式取数”的流程:
- ✅ 旧表更新,新表自动同步(名称不变)
- ✅ 后续要增加其它数据?再写一列公式就行
- ✅ 方便核对:对比新旧名称,一眼看出是否错配
代价只是多写一列公式——熟练后不到1分钟搞定。
看似多一步,实则是以极小代价换高效率、强灵活性和好维护性。
结合本工具的快速匹配,代价不增反减,效果更佳。
5. 高级设置:返回前 N 个匹配结果
默认返回 1 个最相似的匹配项(2列)。
你也可以设置返回前 n 个(n ≤ 5),从左到右按相似度降序排列。
适用场景:
- 名称差异大、匹配不确定时,提供多个候选
- 历史数据混乱、别名多,便于比对
- 需辅助判断最优匹配,避免遗漏
使用建议:
- ✅
n=1:日常推荐,高效清晰 - 🔍
n=2~3:复杂情况,兼顾准确 - ⚠️
n=4~5:不推荐,列多难读,低分项参考价值低
💡 提示:即使返回多个结果,仍可用公式分别查找。建议最终选定一个主用项,保持表格整洁。
该功能让模糊匹配更可控、可选、可追溯,进一步提升灵活性。